Introduction
Fine-tuned BERT-style bidirectional encoders, such as E5, have long dominated text embedding models, delivering state-of-the-art performance for many sequence-level tasks at an accessible cost. However, currently, many of the top performing models on the MTEB leaderboard, a text embedding benchmark for various tasks (retrieval, clustering, classification, etc.) are decoder-only language models at the ~7B scale. These models leverage larger context windows and pretraining on web-scale data.
This post reviews the papers of the following models:
- E5-mistral-7b-instruct
- NV-Embed-7b (currently ranked #1 on MTEB, from Nvidia)
- GritLM-7b
- LLM2Vec
Spotlight on E5-Mistral
The top-performing models share similar principles. Let’s start with E5-mistral, introduced in this paper. Starting with the pretrained Mistral-7B LLM, it’s fine-tuned using LoRA. Models such as Mistral went through extensive auto-regressive pre-training at web scale, which enables them to acquire good text representations, and only minimal fine-tuning is required to transform them into effective embedding models. This contrasts with smaller text encoders, which rely heavily on weakly-supervised contrastive pre-training. This often involves gathering extensive datasets of positive and negative text pairs, typically generated through self-supervised methods, before fine-tuning on a specific downstream task with higher quality data.
Fine-Tuning Details
The fine-tuning process follows standard contrastive learning with cosine similarity, pairing positive examples with random in-batch negatives. Since it’s a decoder-only LLM, an [EOS] token is appended to the query and document, and the final-layer [EOS] vector is extracted as the embedding. In causal attention, where tokens can only attend to previous tokens, the [EOS] embedding effectively represents the entire sequence, akin to the [CLS] token in encoders. An alternative approach could involve modifying the attention mechanism, as we’ll explore later.
The paper also goes in detail on how they generated per-task synthetic data with GPT using instructions which I’m skipping here (worth a read).
Bi-Directional Attention
One key difference of the other works that followed is that all modify Mistral’s causal attention to bidirectional during contrastive training. This is more intuitive for sequence-level tasks like embeddings where each token can attend to any other token in the context. All studies report improved embedding representations as a result. Another key difference is how embeddings are extracted. Instead of relying on the final token representation, these models apply various pooling techniques, such as mean pooling or weighted pooling based on attention scores, to generate more robust embeddings.
A Generalist Embedding Model
A generalist model is one that performs well on different tasks (retrieval, classification, clustering, etc.). This versatility is often achieved by using task-specific instructions during fine-tuning. For example, the model takes the following format:
Instruct: {task_definition}
Query: {query}
When fine-tuning on a retrieval dataset, each query might be prefixed with:
Instruct: Given a web search query, retrieve relevant passages that answer the query
Query: how do solar panels work
The model only adds instructions to queries, not documents. This design allows for offline document indexing while enabling different search behaviors through query instructions.
NV-Embed’s Contribution
NV-Embed (Nvidia) suggests that using in-batch negatives, while effective for retrieval, may not suit other tasks. For instance, in clustering, random in-batch examples might actually be positives. They propose a two-stage training:
- Use in-batch negatives only when training on retrieval tasks
- Avoid in-batch negatives for other tasks
Note: While idea makes sense to me, the paper presents it as a key contribution without providing experimental evidence of its impact (I read the entire thing!). When reading research papers, it’s important to distinguish between interesting ideas and those actually validated through experimental results. The lack of supporting data here suggests this contribution may be less significant than presented.
GritLM: A Hybrid Approach to Generation and Embedding
GritLM differs from the other works by combining generation and embedding tasks in a single model. While I’m not a fan of this idea (will explain why in a bit), it’s worth examining. Typically, fine-tuning a decoder-only LLM for embeddings significantly harms the generation performance. GritLM addresses this by adopting a multi-task learning strategy, fine-tuning the model for both tasks with a hybrid objective that blends bidirectional representation learning and causal generative training.
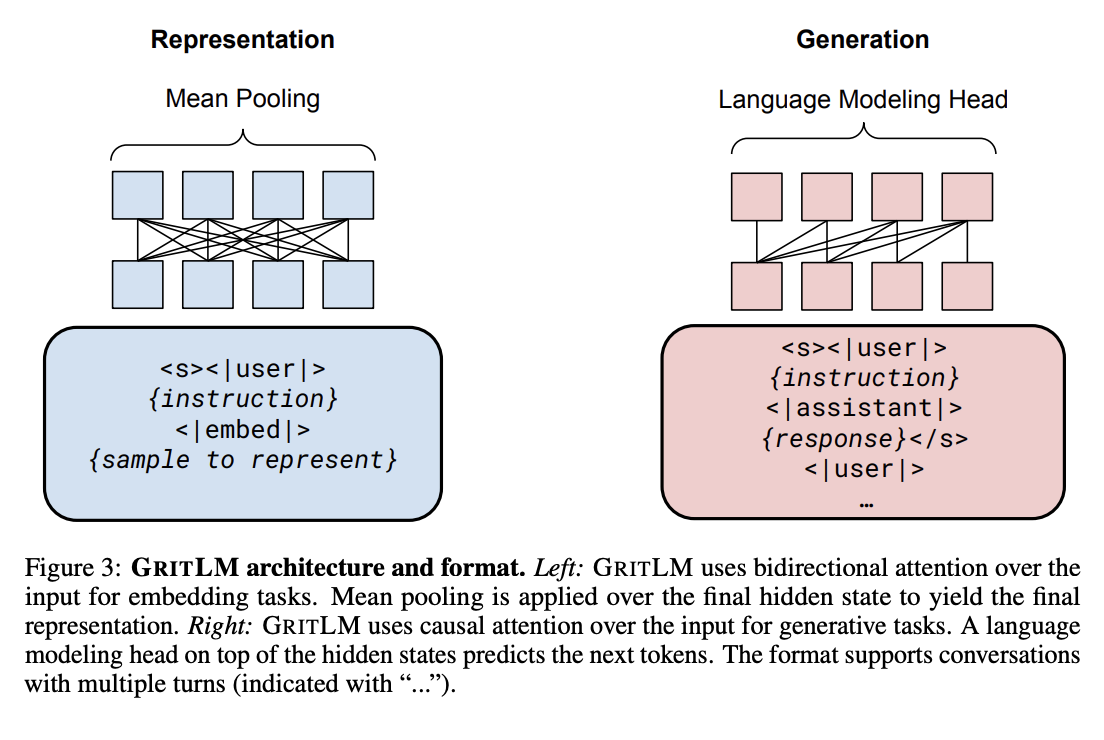
The impressive outcome is that GritLM achieves comparable performance on both tasks to models fine-tuned for each task individually. There is an advantage of having a single model for both tasks. The primary motivation behind this unified approach is to enable more efficient inference, particularly in scenarios like retrieval-augmented generation (RAG). However, this comes at the cost of more computationally expensive training, increased model complexity and storage cost.
Faster RAG with GritLM
In standard RAG workflows, the process involves:
- Embedding documents and indexing them for retrieval
- Retrieving relevant documents for a query and feeding both the query and retrieved documents to the LLM for answer generation
GritLM introduces a unique optimization: during the indexing phase, when embedding each document, instead of storing document text, the key-value states of the model are cached (a form of self-attention caching similar to prompt caching). This enables the system to skip forward passes for indexed documents during the generation inference. However, this approach lacks the flexibility of traditional RAG, where you can freely structure a prompt with instructions, followed by a list of documents and a query, or vice versa. In GritLM’s setup, the query must always come after the documents, as the cached states are tied to the documents and cannot dynamically attend to new instructions or restructured input sequences. Also, for large LLMs, storing key-value states is significantly more expensive than storing typical document texts. (They also tested other forms of caching but found that document caching works the best).
Limitations
While these works are interesting and require much less data to perform very well on a variety of sequence level tasks (retrieval, clustering, classification, etc), there are a couple of limitations related to their adoption:
- Inference and storage costs: The reliance on bigger models increases inference costs. Embeddings with 4096 dimensions further compound storage challenges. (Results with smaller embedding dimensions would be valuable for comparison)
- Specifically for GritLM: Even less practical due to its higher storage costs and limited flexibility
As far as evaluation goes, the MTEB benchmark focuses predominantly on shorter sequences, making it challenging to evaluate on long documents that these models support. There’s also a potential for test set contamination since Mistral was trained on extensive, unspecified datasets derived from the web, which may lead to inflated performance metrics.
Final Thoughts
For single-task use cases, smaller encoders remain highly competitive and practical. While they require more data and careful fine-tuning, synthetic data generation with strong LLMs has made this process both easier and more cost-effective (see this paper from DeepMind for example). In my view, the best trade-off is still a smaller, efficient model for embeddings paired with a larger, more powerful model for generation. That said, for use cases requiring strong performance across a variety of tasks, larger-scale LLMs show great promise as versatile embedding models.